
Can We Scale Predictive Coding? or Why the Brain Might Be Much Wider Than Deep
Published:
📖 TL;DR: The gradients computed by predictive coding converge to backpropagation’s for much wider than deep networks (like the brain), under stable parameterisations.
In this post, I review my 2026 ICML paper On the Infinite Width and Depth Limits of Predictive Coding Networks . The paper is quite technical, so here we focus on explaining the key results at a high level and their implications.
Motivation
Anyone who has taken an introductory AI course should know that at the core of training artificial neural networks is an algorithm called “backpropagation” (BP). While powerful, BP is energy inefficient and “biologically implausible” [1]. In particular, while neurons in brain change their connections (or synapses) only based on neurons they talk to, BP requires propagating “non-local” information through the network.
Predictive coding (PC) is an influential, brain-inspired learning algorithm as an alternative to BP [2]. PC has a long history as a theory of information processing in the brain and is based on the basic idea that neurons minimise their local prediction errors [3].
However, despite some recent encouraging progress [4][5][6], training wide and especially deep PC networks (PCNs) on large-scale datasets competitively with BP remains an open challenge [7]. Indeed, this is the challenge at the heart of the whole field of local learning algorithms.
In asking why local algorithms like PC might be hard to scale, it is natural to look at what has enabled the successful scaling of BP. While scaling laws [8] have arguably been the most important factor, if one looks carefully at the literature and talks to people at frontier AI labs, one realises that model parameterisations derived in “idealised limits” (e.g. infinite width) [9][10][11] are often used in practice.
These theoretically motivated parameterisations not only ensure stable training dynamics across scales, but also enable the empirical transfer of optimal hyperparameters (e.g. learning rate) from small to large models [12], avoiding the prohibitive tuning cost at large scale. If you have heard of \(\mu\)P [9], then this is what I am talking about. I have a separate post on this topic, but it’s not necessary to understand our ICML results.
In this work, we adopted this approach and analysed the infinite width and depth limits of networks trained with PC (as opposed to BP). In particular, we theoretically derive and empirically validate stable parameterisations for wide and deep PCNs, including convolutional networks and transformers.
Key results
Our work has two main results. First, we show that
the set of scalable parameterisations for PC is the same as for BP, in the sense of being numerically stable and learning non-trivial features at large width and depth.
Below is a visual illustration of the result. We start by considering the same set of general parameterisations as in previous work, and find that the subset of parameterisations that are stable (in a well-defined sense) for BP turns out to be the exactly same as for PC.
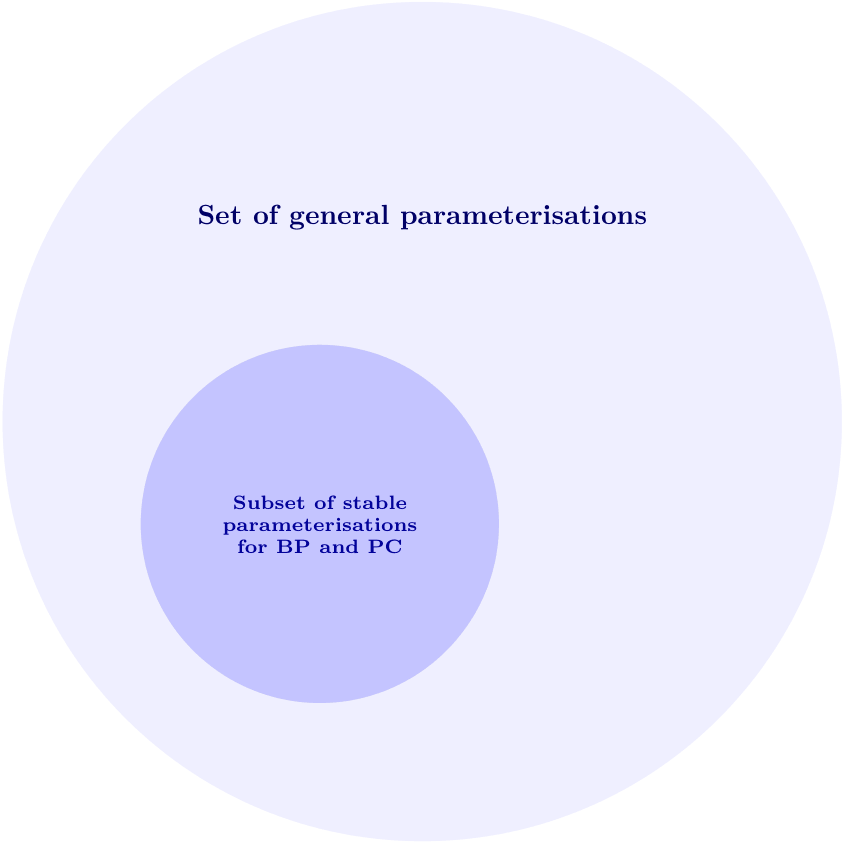 The stable parameterisations for PC are exactly the same as for BP. We start by considering the same set of general parameterisations as in previous work, and find that the subset of stable and "rich" (non-lazy) parameterisations when scaling model width and depth for PC is the same as for BP.
The stable parameterisations for PC are exactly the same as for BP. We start by considering the same set of general parameterisations as in previous work, and find that the subset of stable and "rich" (non-lazy) parameterisations when scaling model width and depth for PC is the same as for BP.
The other main result turns out to be a straightforward consequence:
under of these stable parameterisations, the weight gradients computed by PC converge to those computed by BP in a regime where the model width is much larger than the depth.
Below is an empirical verification of this result. We train linear residual networks with a stable parameterisation on CIFAR-10, and plot the cosine similarity between the PC gradients and the BP gradients as a function of the model width and depth. As predicted by the theory, we see that the gradient alignment converges to 1 for much wider than deep networks.
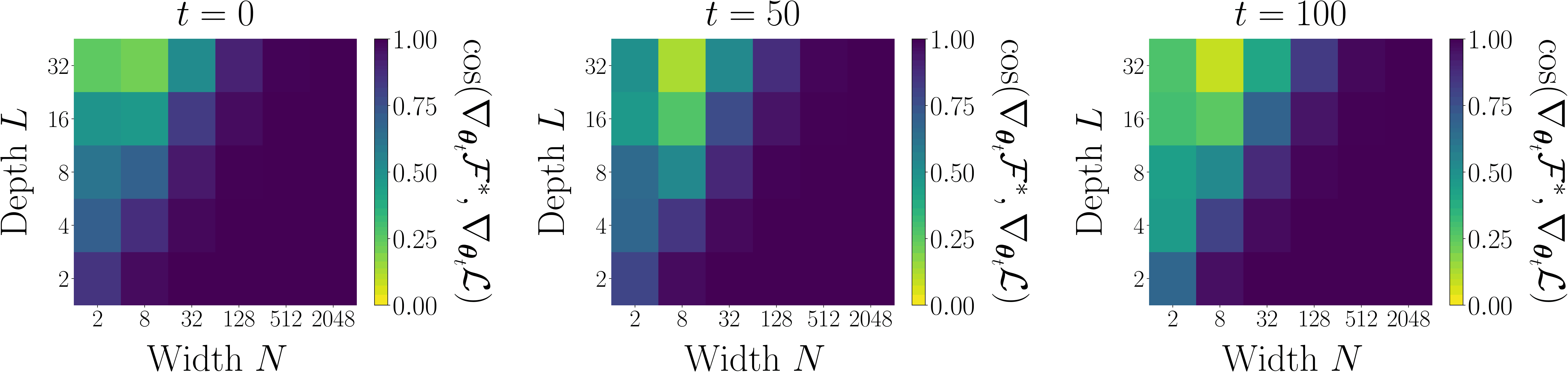 PC converges to BP for wider than deep linear networks, under stable parameterisations. We train linear residual networks on CIFAR-10 with a stable parameterisation. Plotted is the mean cosine similarity over 3 runs between the PC gradients and the BP gradients at different training steps t. See the paper for more details.
PC converges to BP for wider than deep linear networks, under stable parameterisations. We train linear residual networks on CIFAR-10 with a stable parameterisation. Plotted is the mean cosine similarity over 3 runs between the PC gradients and the BP gradients at different training steps t. See the paper for more details.
This result turns out to be surprisingly general (see the figure below): we find that convergence to BP at large width holds for nonlinear networks including CNNs and transformers, trained with different optimisers and loss functions, on small and large-scale datasets (e.g. ImageNet).
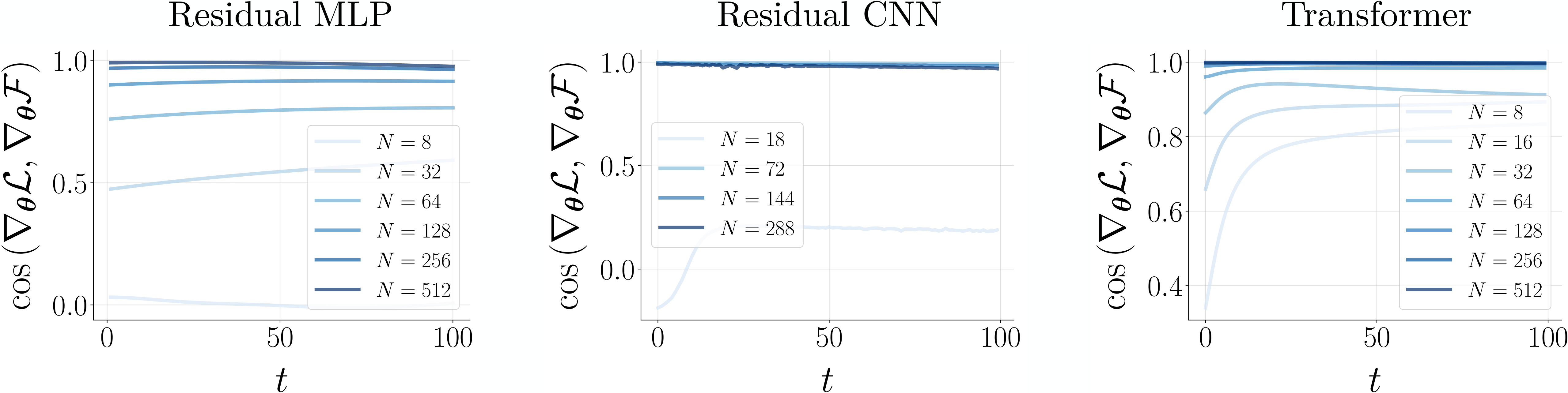 PC still converges to BP for different nonlinear architectures that are much wider than deep, under stable parameterisations. For more details, see the paper.
PC still converges to BP for different nonlinear architectures that are much wider than deep, under stable parameterisations. For more details, see the paper.
Implications
Our results have 2 key implications for the scaling of PC. First:
if one would like to satisfy reasonable notions of stability and feature-learning (“the \(\mu\)P desiderata”) [9], then necessarily the only scalable parameterisation for PC is the same as for BP (i.e. \(\mu\)P), in the sense of being numerically stable and learning non-trivial features at large width and depth.
This means that PCNs trained in practice (with the “standard parameterisation”) cannot be stably scaled in width and depth.
While this result may appear negative, we are also the first (to the best of our knowledge) to show that
BP can be effectively implemented with a local algorithm at scale, for much wider than deep models.
This result is interesting for two reasons. First, modern LLMs have a width (aka embedding dimension) that is at least one order of magnitude larger than their depth. This means that if one could do inference fast with PC (more on this below), then we could speed up model training by a factor ~depth, since the weight updates of PC are parallelisable across layers.
Second, the brain is indeed much wider than it is deep [13], with ~10k synapses per neurons and 6 cortical layers. Our results therefore suggest an elegant way in which biology could do backprop using only local updates.
Limitations & future directions
Our work has still several limitations pointing to future directions. First, while we provided supporting experiments on different nonlinear architectures, our theory relies on linear networks. It could be interesting to see if one could use tools from dynamical mean field theory (as used in previous work) [10][14] to generalise the theory to nonlinear models.
Our results also do not necessarily rule out other notions or desiderata of a stable and feature-learning parameterisation, where PC might not converge to (and perhaps be better than) BP.
The main bottleneck of PC remains the computational cost of converging its iterative (optimisation-based) inference process. While there has been some recent work accelerating this on GPUs [6][15], it is clear that to beat BP we need analog implementations. Whether PC can be implemented on such hardware remains an important open question.
The standard transformer we tested is not biologically plausible since the self-attention mechanism [16] is highly non-local. It would be interesting to investigate attention mechanisms where the softmax is itself the gradient of some energy function [17]. These mechanisms are closely related to modern Hopfield networks [18] and have some bio-plausible implementations [19].
References
[1] Lillicrap, T. P., Santoro, A., Marris, L., Akerman, C. J., & Hinton, G. (2020). Backpropagation and the brain. Nature Reviews Neuroscience, 21(6), 335-346.
[2] Millidge, B., Seth, A., & Buckley, C. L. (2021). Predictive coding: a theoretical and experimental review. arXiv preprint arXiv:2107.12979.
[3] Rao, R. P., & Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature neuroscience, 2(1), 79-87.
[4] Qi, C., Lukasiewicz, T., & Salvatori, T. (2025). Training deep predictive coding networks. In New Frontiers in Associative Memories.
[5] Innocenti, F., Achour, E. M., & Buckley, C. L. (2025). $\mu$PC: Scaling Predictive Coding to 100+ Layer Networks. Advances in Neural Information Processing Systems 38.
[6] Goemaere, C., Oliviers, G., Bogacz, R., & Demeester, T. (2025). ePC: Overcoming Exponential Signal Decay in Deep Predictive Coding Networks. arXiv preprint arXiv:2505.20137.
[7] Pinchetti, L., Qi, C., Lokshyn, O., Emde, C., M'Charrak, A., Tang, M., ... & Salvatori, T. (2025). Benchmarking Predictive Coding Networks--Made Simple. In International Conference on Learning Representations (Vol. 2025, pp. 35701-35734).
[8] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., ... & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
[9] Yang, G., & Hu, E. J. (2021). Tensor programs iv: Feature learning in infinite-width neural networks. In International Conference on Machine Learning (pp. 11727-11737). PMLR.
[10] Bordelon, B., & Pehlevan, C. (2022). Self-consistent dynamical field theory of kernel evolution in wide neural networks. Advances in Neural Information Processing Systems, 35, 32240-32256.
[11] Dey, N., Zhang, B., Noci, L., Li, M., Bordelon, B., Bergsma, S., ... & Hestness, J. (2026). Don't be lazy: CompleteP enables compute-efficient deep transformers. Advances in Neural Information Processing Systems, 38, 137707-137739.
[12] Yang, G., Hu, E., Babuschkin, I., Sidor, S., Liu, X., Farhi, D., ... & Gao, J. (2021). Tuning large neural networks via zero-shot hyperparameter transfer. Advances in Neural Information Processing Systems, 34, 17084-17097.
[13] Suzuki, M., Pennartz, C. M., & Aru, J. (2023). How deep is the brain? The shallow brain hypothesis. Nature Reviews Neuroscience, 24(12), 778-791.
[14] Bordelon, B., & Pehlevan, C. (2022). The influence of learning rule on representation dynamics in wide neural networks. arXiv preprint arXiv:2210.02157.
[15] Pinchetti, L., Frieder, S., Lukasiewicz, T., & Salvatori, T. (2026). Faster Predictive Coding Networks via Better Initialization. arXiv preprint arXiv:2601.20895.
[16] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[17] Singh, R., & Buckley, C. L. (2023). Attention as implicit structural inference. Advances in Neural Information Processing Systems, 36, 24929-24946.
[18] Ramsauer, H., Schäfl, B., Lehner, J., Seidl, P., Widrich, M., Adler, T., ... & Hochreiter, S. (2020). Hopfield networks is all you need. arXiv preprint arXiv:2008.02217.
[19] Kozachkov, L., Slotine, J. J., & Krotov, D. (2025). Neuron–astrocyte associative memory. Proceedings of the National Academy of Sciences, 122(21), e2417788122.