
PhD Reflections
Published:
Having recently submitted my PhD thesis, I’ve been thinking a lot about my PhD experience. Here I would like to share some reflections. Needless to say that this is my own, biased experience, and PhDs can vary greatly depending on the field, lab, supervisor, etc.
My PhD in a nutshell
My PhD research focused mainly on a specific brain-inspired algorithm for training deep neural networks called “predictive coding” (PC), as an alternative to standard backpropagation (“backprop” or BP). Coming from a psychology and neuroscience background, I felt very dissatisfied with the biological implausibility of backprop and found in PC a compelling framework for thinking about brain function. At the same time, I became fascinated with the relative success and mathematical simplicity of artificial neural networks (note that this was before the “ChatGPT-3 moment” in 2022). So naturally, my main PhD goal became to determine whether PC (and similar algorithms) could be scaled as successfully as backprop, on deep models and large datasets.
Despite some cool findings and a lot of fun had in the way, my work in the past 3 years strongly suggests that the answer to this question is “no”. More precisely, while deep neural networks trained with PC clearly show some advantageous properties over BP, these benefits are either negated or become computationally prohibitive at large scale, at least on standard digital hardware (GPUs). It’s worth highlighting one of these benefits that my work clearly established, with the help of my amazing collaborator El Mehdi Achour. In fact, I think this is the coolest—even if definitely not the most impactful—result of my PhD, in the sense of it being very surprising or unexpected.
First we need to understand how PC differs from BP. It all boils down to how inference is done. While in BP inference is simply modelled by a fixed feedforward pass, PC performs inference by optimisation of the network activities, as shown in the schematic animation below.
 PC inference. Before learning or weight updates, PC performs inference by equilibration of the network activities (via gradient-based minimisation).
PC inference. Before learning or weight updates, PC performs inference by equilibration of the network activities (via gradient-based minimisation).
Soon after I developed my first theory of PC as a trust-region optimiser [1] in the first year of my PhD, a now highly-cited Nature paper [2] from Rafal Bogacz’s group—which I now joined and which like the lab I was based in also specialises in PC—came out suggesting that this inference process confers many benefits to PC (and similar energy-based algorithms) over BP. The claim that particularly caught my eye was that the PC inference process enabled faster training (or learning convergence) of deeper networks than BP. This was supported by conceptual arguments and highly selected experiments.
While I agreed with the basic intuition that the inference process of PC could provide some benefits for learning based on my own work, it was certainly not clear whether this was always the case. Indeed, there were already a few conflicting results in the literature showing that these learning speed-ups with PC were not consistently observed depending on the dataset, model, and optimiser [3].
It was clearly not the whole story. So I dug deeper. The result was a theoretical and empirical study of the geometry of the landscape on which PC effectively learns (i.e. at equilibrium or convergence of the inference dynamics) [4], with surprising and enlightening findings. I felt that the landscape perspective was the simplest and most efficient way of reasoning about the myriad of factors affecting convergence speed, including the architecture, initialisation, optimiser, learning rate, etc.
So what did we find? In brief, it turned out that very degenerate (flat) saddle points in the loss landscape of deep networks became benign or much easier to escape—and more so at larger depth—in the effective landscape optimised by PC. The figure below from our NeurIPS 2024 paper shows some toy examples illustrating this result.
 Toy examples illustrating the result that the saddle at the origin of the PC learning landscape does not grow degenerate (flatter) with depth as in the loss landscape. See the paper for more details.
Toy examples illustrating the result that the saddle at the origin of the PC learning landscape does not grow degenerate (flatter) with depth as in the loss landscape. See the paper for more details.
Did this validate the general claim that PC trains deeper networks faster than BP? Mostly “No”. The theory predicted very reliably that such speed-ups could be expected only under very specific and mostly non-realistic conditions on the architecture, initialisation, optimiser, etc.—for example, for deep non-residual networks initialised near the origin and trained with (S)GD (as shown in the figure above). The theory also clearly explained the speed-up reported in the Nature paper by Song et al. (2024) as a consequence of the narrow (and non-realistic) width of the networks tested.
Despite the modest impact, we still saw the result as super cool, in that we effectively showed that higher-order information about an outer optimisation problem (learning) can be implicitly computed by an inner optimisation process (inference) on the same objective using only first-order, local information.1 More succinctly, multiple inference gradient updates allow for a higher-order learning weight update. This is a very interesting result not only from a theoretical perspective, but also because it suggests a biologically plausible mechanism for how the brain could deal with a very ill-conditioned learning problem. In this work, we also corrected a fairly common mistake in previous theoretical analyses of the learning dynamics of PC,2 (which confused me for many months at the start of my PhD).
So what was next? This work showed that we would probably not get any speed-ups with PC at scale compared to state-of-the-art architectures (ResNets) and training methods (e.g. Adam). However, as long as we could train at large scale, perhaps this was okay, and there was still a chance that other claimed benefits of PC would hold [2]. Yet, the problem was that at the time we could not train very deep (10+ layer) PC networks (PCNs), even on toy tasks. It was not exactly known why, but there was an intuition among our group and others that the inference communication would slow down and perhaps vanish with model depth. So while we had just gotten a handle on the learning dynamics of PCNs, we were still missing the other half of the picture: an understanding of their inference dynamics.
So we got to work and did just that, delivering a theory of the inference landscape and dynamics of PCNs—which just got accepted at NeurIPS this year [5]. One key finding was that the inference landscape generally grew more ill-conditioned with model size (particularly depth) and training time, making convergence practically impossible. Another, perhaps less surprising, but as it turned out critical result was that the forward pass of typical PCNs people were training tended to vanish/explode with depth (depending on the model). We tried super hard to solve these issues, but after many months we concluded that there was a fundamental trade-off between them (see the paper for more details). The forward pass was absolutely crucial for training so we prioritised ensuring its stability. To our surprise, by “just” fixing this, we managed to train 100+ layer PCNs on simple tasks with little tuning and competitive performance compared to current benchmarks (see “μPC” in the Figure below).
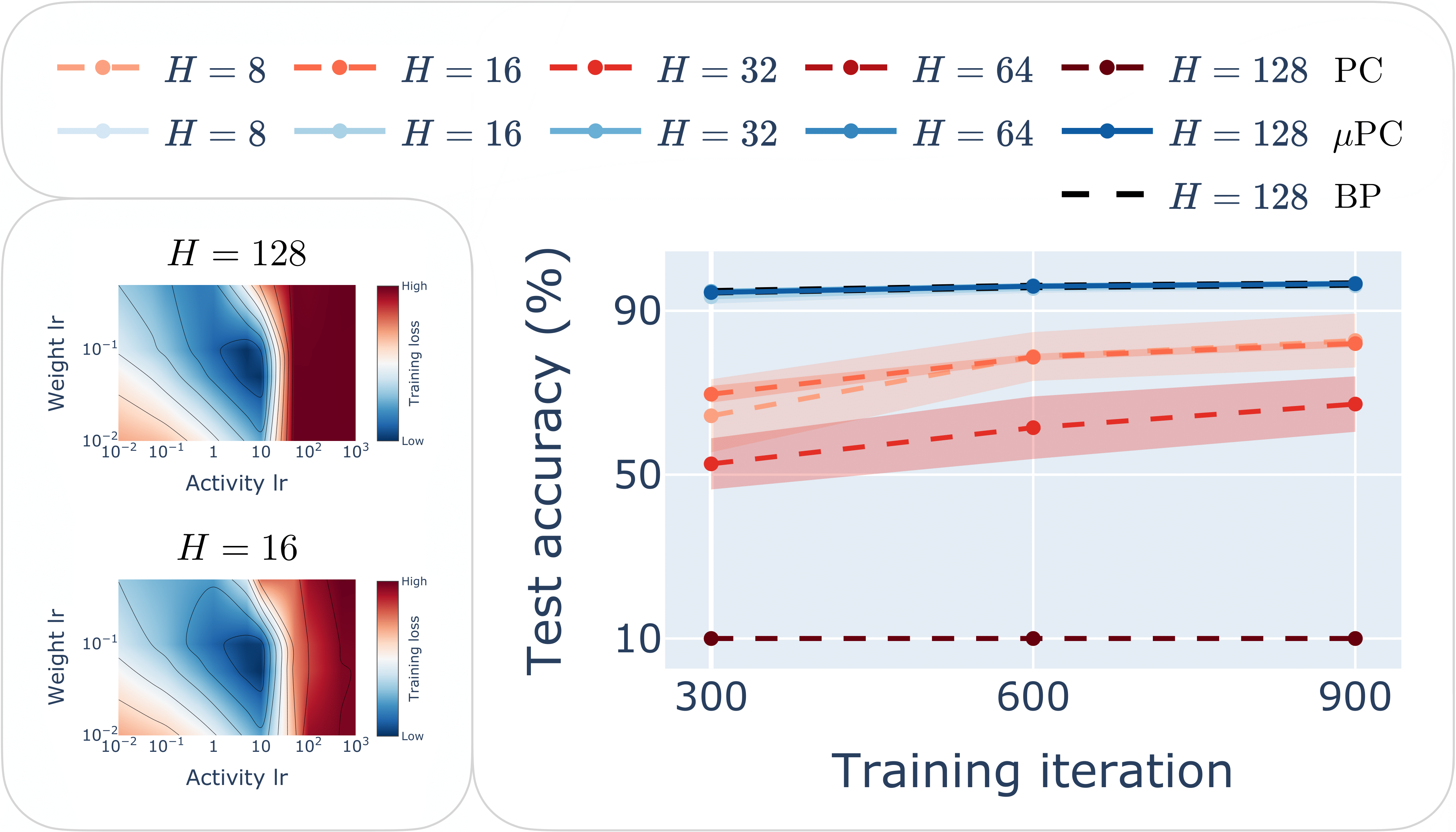 "μPC" enables stable training of 100+ layer ResNets with zero-shot learning rate transfer. (Right) Test accuracy of ReLU ResNets with depths H = {8, 16, 32, 64, 128} trained to classify MNIST for one epoch with standard PC, μPC and BP with Depth-μP. (Left) Example of zero-shot transfer of the weight and activity learning rates from 16- to 128-layer Tanh networks. See the paper for more details and results.
"μPC" enables stable training of 100+ layer ResNets with zero-shot learning rate transfer. (Right) Test accuracy of ReLU ResNets with depths H = {8, 16, 32, 64, 128} trained to classify MNIST for one epoch with standard PC, μPC and BP with Depth-μP. (Left) Example of zero-shot transfer of the weight and activity learning rates from 16- to 128-layer Tanh networks. See the paper for more details and results.
This was very encouraging. After all, to the best of our knowledge such deep networks had never been trained before with a brain-inspired algorithm, even on simple tasks. Does this mean that we were done? Far from it! While this was a step in the right direction, a lot of work still needs to be done to show that PC can scale, including testing on larger datasets (and not just models) and looking at transformers or equally expressive architectures. Nevertheless, I don’t think that these questions are what is fundamentally holding PC (and similar algorithms) back.
The real blocker is hardware: the way PC works is ultimately at odds with GPUs and digital hardware more generally. PC inference is an inherently sequential process that lends itself more easily to a kind of analog, thermodynamic, or neuromorphic hardware that exploits physics (including intrinsic system noise) to equilibrate fast, along the lines of what companies like Normal Computing and Extropic are trying to do. True breakthroughs on these alternative algorithms will have to come from hardware and algorithm codesign, where research efforts should be more focused on. This is, by the way, also why Deep Equilibrium Models [6], which showed a lot of promise, failed to be widely adopted: because they prioritised memory over compute, leading to slower inference.3
Lessons learned
So what did I learn from this journey? Here are the most important, high-level lessons:
- Understand things deeply. Perhaps obviously, this is almost the purpose of a PhD. “Anyone” can have an rough, good, or even detailed grasp of a concept, method or theory, but only deep, prolonged research and thinking can give you the full picture necessary to identify important knowledge gaps that need to be filled or questions that need to be answered. Of course it’s important to know when to go deep given the high time investment, but this is something that can only be improved with research experience.
- Confusion is a good signal. Being confused could mean that you have a misunderstanding or gap in knowledge, in which case you can go and fix it. Or it could also mean that there is a mistake or problem with existing work, in which case you have just found a research knot to unravel and possibly a non-trivial contribution to make. For me this source of confusion is what most often led to research breakthroughs.
- Embrace interdisciplinarity. As we just discussed, a PhD forces you to “go deep”. However, every once in a while, it’s good to step back, zoom out and keep yourself up to date with developments in adjacent fields. Personally, I would say that all my “most creative” ideas came from combining or adapting methods from other fields (e.g. loss landscape theory of neural networks), and this would not have been possible if I didn’t read widely.
- Trust theory that is validated by experiments. It’s tempting to just follow theory without looking at experiments (or even think that the experiments are “wrong”). It is equally tempting to treat your experiments as an oracle. I found that a sweet middle ground is best, namely theory that is close enough to practice to be tested by experiments. Such theories also allow you to iterate very quickly as you can have feedback from data.
- Don’t expect your research progress or output to be linear. PhD students can have very high standards for themselves. Seeing other PhDs publish several papers a year can make you think that you’re not being productive enough or might not even be suited for research, especially at the beginning of your PhD. Besides the fact that you shouldn’t compare yourself to others (in research or life), this line of thinking assumes that research progress (or output) is linear. If (say) you’re aiming for 3 papers in a 3-year PhD, it means that you should publish one paper per year. However, like many other things, research efforts compound. So expect progress to be slower at first and suddenly skyrocket later on. This compounding is not unlimited of course (we have only so much time). I would also say that aiming for more than 3 first-author, high-quality papers per year is likely to reduce the quality of the work, although this can depend on the type of papers.
- Try always the simplest thing first. As a starting PhD student, I found it tempting to try to solve many problems at once and build a complicated solution. However, in research as in again many other things in life, the best thing to do first is to take the next simplest step and add complexity as needed. Live by Occam’s razor.
Concluding reflections
Given my PhD conclusion that PC is at present incapable of providing any practical benefits over BP, do I regret having worked on this particular topic? Not at all. First of all, I achieved my main research goal: I started with a question, which in my mind was important, and managed to answer it to my personal satisfaction. While I would have liked, like any starting PhD student, to revolutionise the field, I am more than content to have achieved what I set out to do and to have made substantial knowledge contributions. Moreover, I managed to make some minor contributions to the more general field of AI.
Second, a PhD is more about learning how to do research than the particular field of research one engages with. An ability that I think is not appreciated enough from a well-done PhD is the gained confidence to master any field within your discipline(s), along with good judgment about research directions. This is likely to be poor at the start of the PhD, and it’s why it’s common to feel like you don’t know what you’re doing, hitting dead ends one after another. It’s an unspoken reason why many Big Tech research and engineering positions require PhDs: because you want people that make strategic decisions about project ideas given time and resource constraints. I also learned a ton of useful skills from this PhD that I think it would not have been possible (or super hard) to learn otherwise, both on the technical and non-technical side.
In closing, I would like to highlight arguably one of the most important factors in the success (and enjoyment) of a PhD—at least definitely for mine. And that is the people. Your main supervisor is of course crucial, and your potential relationship is something that ideally you would think about before starting a PhD. Personally, I benefited a lot from close guidance in the first year, which my supervisor was willing and happy to give. As I developed more expertise and independence of thought, however, he gave me the freedom to pursue my own ideas. It’s hard to know whether a supervisor will be a good match in advance, but doing some research into the lab and talking to previous students can help.
Beyond supervision, I think that collaborations are underrated. While the nature of a PhD is inevitably individual (you are ultimately assessed on your main contributions), I think it can be great to seek collaborations with other peers, especially when you have different strengths (and so you can independently contribute to different parts of a project without stepping too much on each other’s toes). Personally, I benefited a lot from collaborations with other peers in my lab as well as colleagues met at conferences. And it’s not just a question of productivity. Bouncing ideas back and forth with another person makes the whole research process much more fun and exciting, as this recent Nature piece argues.

References
[1] Innocenti, F., Singh, R., & Buckley, C. (2023). Understanding predictive coding as a second-order trust-region method. In ICML Workshop on Localized Learning (LLW).
[2] Song, Y., Millidge, B., Salvatori, T., Lukasiewicz, T., Xu, Z., & Bogacz, R. (2024). Inferring neural activity before plasticity as a foundation for learning beyond backpropagation. Nature neuroscience, 27(2), 348-358.
[3] Alonso, N., Millidge, B., Krichmar, J., & Neftci, E. O. (2022). A theoretical framework for inference learning. Advances in Neural Information Processing Systems, 35, 37335-37348.
[4] Innocenti, F., Achour, E. M., Singh, R., & Buckley, C. L. (2024). Only strict saddles in the energy landscape of predictive coding networks?. Advances in Neural Information Processing Systems, 37, 53649-53683.
[5] Innocenti, F., Achour, E. M., & Buckley, C. L. (2025). $\mu$PC: Scaling Predictive Coding to 100+ Layer Networks. arXiv preprint arXiv:2505.13124.
[6] Bai, S., Kolter, J. Z., & Koltun, V. (2019). Deep equilibrium models. Advances in neural information processing systems, 32.
The higher-order information, in case you’re wondering, comes the fact that the escape direction for the degenerate saddles is found in a nth-order derivative which grows linearly with the depth of the network. ↩
The mistake was a decomposition of the PC objective (energy) into a sum of internal energies and the MSE loss. This relationship only holds at the forward pass initialisation of the activities and breaks down during inference. Our work showed that the total energy at the inference equilibrium turns out to be equal to a rescaled MSE loss. We proved this for deep linear networks and empirically validated the theory on nonlinear networks with various datasets and architectures. ↩
This is the opposite of what modern (sparse) Mixture of Experts (MoEs) do in LLMs: they increase memory cost (number of experts) to save compute at training and inference time, so that you have more capacity or parameters for the same amount of compute. ↩